clp日志压缩
我们在做监控日志平台时提出两个目标:高压缩率并且不放弃聚合查询的效率;为通用应用/文本日志找出错误模式以服务应用状态自动感知(发布和回滚)。
为了达到目的#1,我们放弃了elastic search,选择了clickhouse(enable zstd)或自己写hdfs(enable zstd)。而为了目的#2,有两种做法,一种是让用户交互式配置不同的日志的模式,在日志落盘前进行解析(靠近日志源的地方分布式处理,集中式处理很容易成为瓶颈难以维护和扩展),另一种想法是通过自动分析出重复的pattern,主要想通过论文中的一些日志解析模块。参考的论文有:
- logpai
- logMerge
- clp
最近clp的这篇帖子(来自uber)介绍了通过clp进行日志解析,并提高了存储效率的做法。本文就介绍clp的论文原理和主要做法。
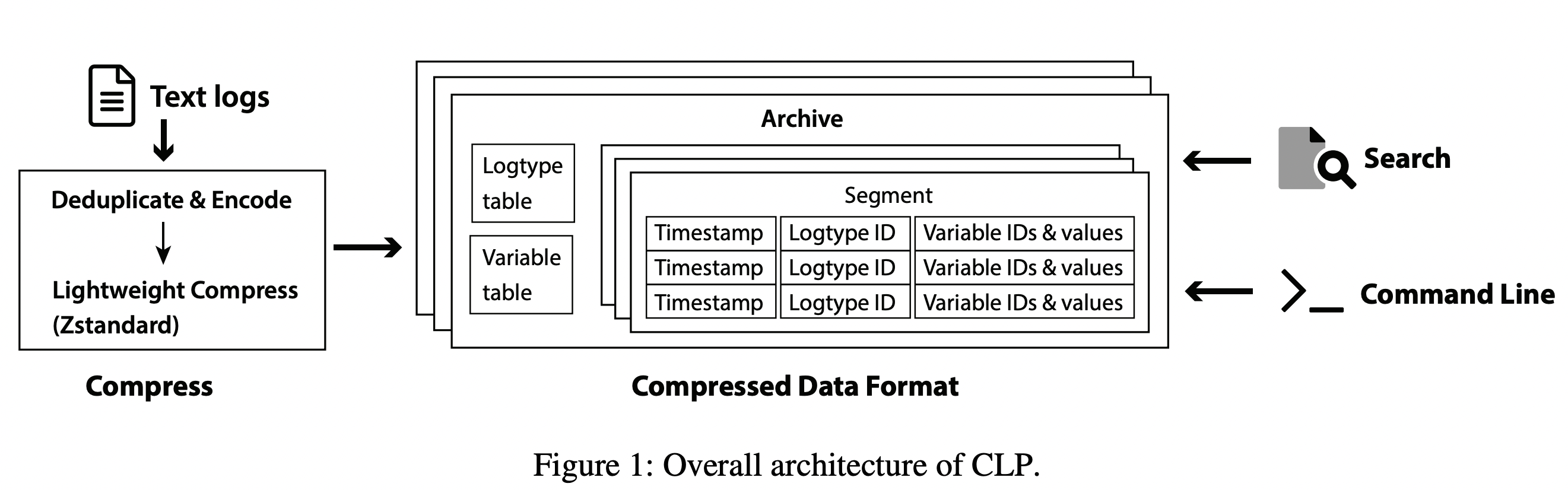
首先uber说明,他们用clp来处理文本日志,结构化日志进了他们的clickhouse的日志系统。clp文章的想法是日志可以分为日志类型(logtype, lt),若干schema变量,和数值型,具体例子是我们平时的文本日志写法都是用log.fmt(“template”, formated_value)。那么如果我们能把这些template抽取出来,和实际的变量分开,编码一下,再使用列式压缩存储。这种做法原理上比简单的logline应用zstd的好处是,clp可以把Logtype整体压缩,简单logline zstd只能压缩部分。

一个典型的hadoop/spark task分配的日志
对应的clp处理的过程和最终的格式如下:

这里数值型和字典变量是分别处理的,主要是考虑数值型的变量很难通过字典变量(大多是cardinality有限的字符串)编码得到有效的提炼。所以数值型的变量的做法是通过一些在rfc754之上改进的encoding方式后放在encoded logmessage中的,而字典变量在encoded logmessage中只存一个索引。
写入
如上原理,logtype的区分就很重要了。clp论文有开源代码,它的做法挺简单的,定一些间隔符。除此之外,还有一些做法可以参考
- 在代码checkin之时就通过code scan的方式把代码中的写日志的地方解析出来,每个写代码的logtemplate进行收集。比如把这步集成在PR/CICD之中,PR merge时和把logtemplate收集到线上的log meta server中,甚至可以增加一些annotation。这种方式好处是可以保证日志类型从客户端就能发送过来,不需要实时分析。 缺点则是:对于开发极端,这种收集到线上meta server的方式显得过于笨重,难以在本机直接使用。另外实施要求公司对开发工具链已经有比较好的建设,多语言的支持也会比较慢。
- 用户通过自定义的方式配置。比如k8s annotation中制定对日志文件的解析方式,在客户端通过agent进行解析,得到logtype和原始数据,这种缺点是很多情况下一个文件里有多个type,这就难以配置了。
- 类似Fp-Tree,使用一些日志解析算法进行分析提取。一般是offline分析提取模式和在线使用已经学习的模式的方式。
根据处理的位置:
- 定制日志库,在日志发送处进行logtype分析,尽量无需配置。这也是uber的做法(他们还在日志库里做了一些优化,参看引用文章)。对于原生开源工具难以定制日志库的,同样方式可以放在服务端之前处理完。
- 在服务器端处理,服务器端同时有写入操作,实现要注意性能影响。
落盘
clp对日志处理之后,分别落盘:
todo: 本地编译一个clp,输入一些日志,从文件名字和binary结构来分析下。
查询
clp日志的存储带来一个问题就是日志不是以原文的方式存着的(以zip/zstd这种压缩方式的由于对上层应用是透明的,也可以认为是原文存放)。如何处理查询就成了一个重要的问题
典型的query做法是用户提供logtype来查询,可以对字典变量做正则,数值变量做比较。如下query
 通过query translate成若干个可能的logtype,都发送给存储去查询。当然有一些会没match上shortcurcuit掉。查询步骤顺序为
通过query translate成若干个可能的logtype,都发送给存储去查询。当然有一些会没match上shortcurcuit掉。查询步骤顺序为
- 先找logtype表,若不匹配就跳过
- 再根据查询条件找字典变量表
- 根据符合logtype和字典变量的logline,decompress进行匹配(这里依然会有可能匹配不上,比如数值变量在第一步和第二步里就是处理不了的)。
![]()
有趣的是,文中说到,logtype查询时间相比字典变量表查询可以忽略不计,而字典变量表查询时间相比segment(即logline解压后的查询)又是可以忽略不计的。
优化
从这个查询过程来看,首先得logtype匹配精准才能有效切精细的查出想要的日志,用户应该提供尽量精确的logtype来提高查询速度。另外,文中提到logtype的表实际中是不大的(理论上也是合理的,日志毕竟是template少,而实际日志行特别多的数据类型,但是实际上应该通过上述的落盘处有个感性认识),所以logtype表查询并没有使用任何索引,而是直接把用户输入的查询变换完暴力全表撸一遍。
应用在公司项目中
uber对结构化日志使用clickhouse,文本日志使用clp。在ebay我们的区分更多的在查询端,需要周环比的快速聚合能力的全结构化日志(叫事件)放在clickhouse中,原始日志在自己写的文件中。clp明显可以用来处理文本日志,至于和clickhouse直接存裸日志的对比,以及能否在clickhouse上应用clp的思路后续做一些实验。
应用
https://www.uber.com/en-FR/blog/reducing-logging-cost-by-two-orders-of-magnitude-using-clp/
dremel paper: columnar的文件设计 https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36632.pdf